Businesses worldwide are swiftly embracing the potential of large language models (LLMs) like OpenAI’s ChatGPT, Anthropic’s Claude, and AI12Lab’s Jurassic to enhance various business functions such as market research, customer service, and content generation. However, deploying an LLM application at an enterprise scale demands a distinct set of tools and insights compared to traditional machine learning (ML) applications.
For executives and business leaders aiming to maintain brand consistency and service quality, a comprehensive understanding of how LLMs function and the pros and cons of different tools within an LLM application stack is essential. In this article, we provide a fundamental overview of the high-level strategy and tools required to develop and operate an LLM application tailored to your business needs.
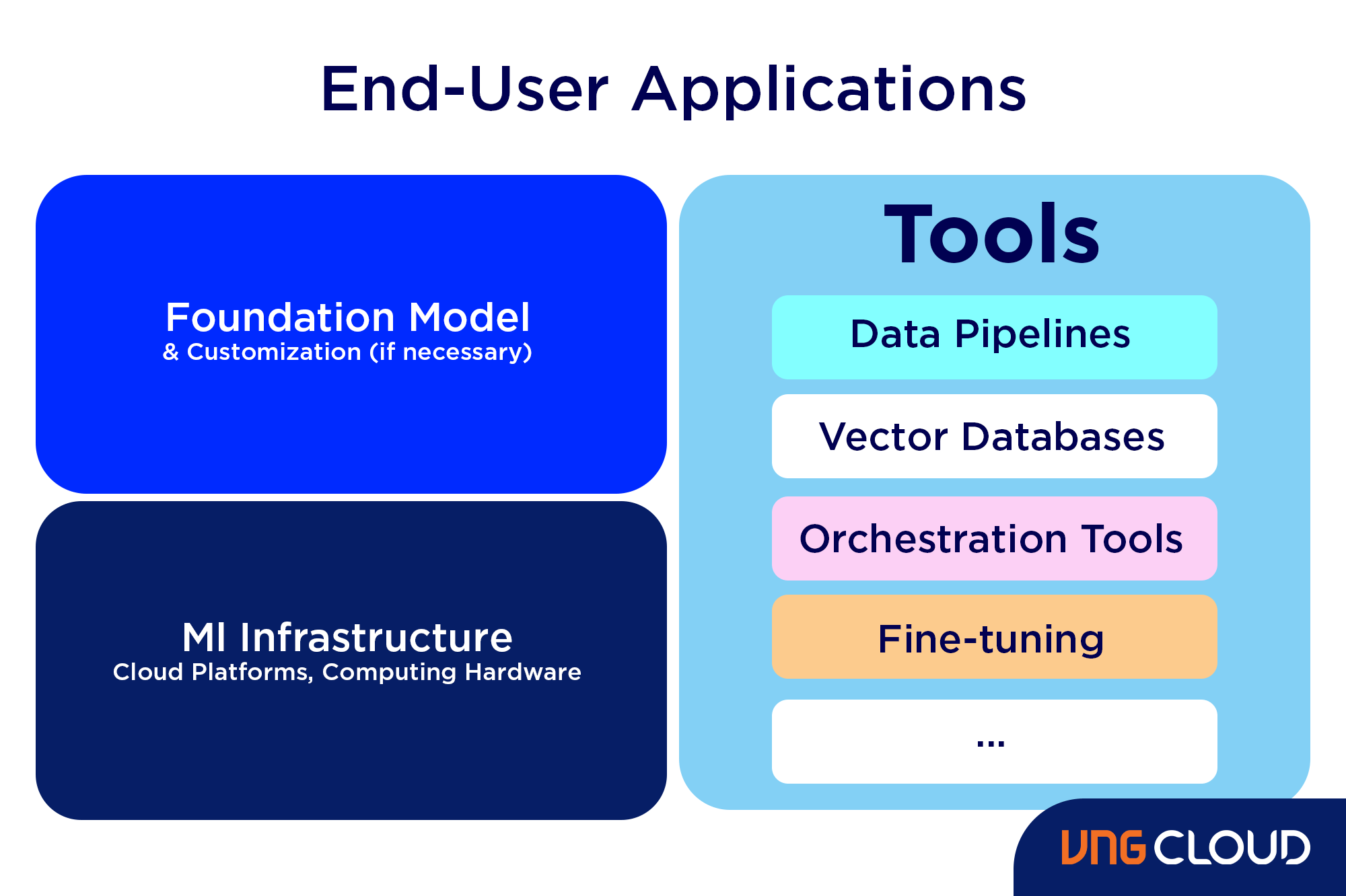
4 steps to develop LLM applications
Developing LLM applications involves four fundamental steps:
- Select an appropriate foundation model: The choice of the foundational model is pivotal as it determines your LLM application's performance.
- Customize the model: Fine-tune or augment the model with additional knowledge to align it with your specific requirements.
- Establish ML infrastructure: This step involves setting up the necessary hardware and software, including semiconductors, chips, cloud hosting, inference, and deployment platforms, to run your application effectively.
- Enhance with additional tools: Integrate supplementary tools that enhance your application's efficiency, performance, and security.
Now, let's explore the corresponding technology stack for these steps.
1. Select an Appropriate Foundation Model
Selecting the right foundation model for your Large Language Model (LLM) application involves several considerations. There are two main categories of foundation models: proprietary and open source.
Proprietary models, like OpenAI's GPT models, Anthropic's Claude models, and AI21 Labs' Jurassic models, are owned by specific companies and usually come at a cost. Open-source models, such as Meta's Llama models, Technology Innovation Institute's Falcon models, and Stability AI's StableLM models, are accessible for free, but some may have usage restrictions, like limited availability for research purposes or specific commercial use criteria.
To navigate this selection process, you can follow these steps:
- Choose Between Proprietary and Open-Source Models: Proprietary models are often more capable but come with a price tag and might lack transparency in their code. Open-source models, while free, might receive fewer updates and less developer support.
- Determine Model Size: Consider the task complexity. Larger models excel at knowledge-intensive tasks but require more computational resources. Start with experimenting on larger models and scale down if their performance meets your requirements without straining resources.
- Select a Specific Model: Begin by reviewing general benchmarks to shortlist models for testing. Then, conduct specific tests tailored to your application's needs to identify the best fit.
Careful consideration in each of these steps ensures that the foundation model chosen aligns perfectly with your LLM application's demands.
2. Customize the Model
Customizing a foundation language model can significantly enhance its performance for specific use cases. Here are some scenarios where customization might be necessary:
- Domain Optimization: Tailoring the model's vocabulary to specific domains, such as legal, financial, or healthcare, enables it to better comprehend and respond to user queries within those domains.
- Task-specific Customization: For tasks like generating marketing campaigns, providing the model with branded marketing examples helps it learn the appropriate patterns and styles relevant to your company and audience.
- Tone of Voice Customization: If a specific tone of voice is required, the model can be customized using a dataset containing samples of the desired linguistic style.
There are three methods to customize a foundation language model:
- Fine-tuning: Involves updating the model's weights using a domain-specific labeled dataset (around 100-500 records), enhancing its performance on tasks represented by the dataset.
- Domain Adaptation: Involves updating the model's weights using a domain-specific unlabeled dataset containing extensive data from the relevant domain.
- Information Retrieval: Enhances the model with closed-domain knowledge without retraining it. The model can retrieve information from a vector database containing relevant data.
Fine-tuning and domain adaptation require substantial computing resources and technical expertise, making them suitable for larger companies. Smaller businesses often opt for augmenting the model with domain knowledge through a vector database, a more accessible approach detailed later in this article's section on LLM tools.

3. Establish ML Infrastructure
Establishing the Machine Learning (ML) infrastructure, a crucial component of LLMOps, encompasses cloud platforms, computing hardware, and resources essential for deploying and operating Large Language Models (LLMs). This aspect gains prominence, especially if you're considering open-source models or customizing the model for your specific application. Adequate computing resources are vital for tasks like fine-tuning and running the model effectively.
Various cloud platforms, such as Google Cloud Platform, Amazon Web Services, and Microsoft Azure, offer services tailored for deploying LLMs. These platforms feature:
- Pre-trained Models: Models that can be fine-tuned to suit your unique application requirements.
- Managed Infrastructure: Services that handle the underlying hardware and software, ensuring seamless operation.
- Monitoring and Debugging Tools: Tools and services facilitating efficient monitoring and troubleshooting of your LLMs.
The computational resources needed hinge on factors like the model's size, complexity, desired tasks, and the scale of deployment within your business activities. These elements determine the infrastructure requirements for successful deployment and operation.

4. Enhance with Additional Tools
Augmenting the performance of your Large Language Model (LLM) application involves leveraging additional tools tailored to optimize its capabilities.
Data Pipelines
Incorporating your data into your LLM product requires a robust data pre-processing pipeline. These tools encompass connectors to fetch data from diverse sources, a data transformation layer, and downstream connectors. Established providers like Databricks and Snowflake, along with newcomers like Unstructured, facilitate the integration of vast, varied natural language data, such as PDFs, chat logs, or HTML files. These pipelines centralize data into accessible formats for seamless utilization by LLM applications.
Vector Databases
For processing large documents beyond the LLM's capacity, vector databases play a pivotal role. These storage systems convert extensive documents into manageable vectors or embeddings via data pipelines. LLM applications can then query these databases, extracting pertinent information. Notable vector databases like Pinecone, Chroma, and Weaviate empower businesses to extract essential insights efficiently.
Orchestration Tools
To construct effective queries for LLM applications, orchestration tools are essential. These tools streamline the creation of prompts, incorporating developer-defined prompt templates, few-shot examples, information from external APIs, and relevant documents from vector databases. Providers like LangChain and LlamaIndex offer frameworks that simplify this process, ensuring streamlined management and execution of prompts.
Fine-tuning
Customizing LLMs for specific domains, like medicine or law, enhances their precision. Fine-tuning on domain-specific datasets refines their understanding, enabling the generation of contextually relevant text. While this process can be resource-intensive, platforms such as Weights & Biases and OctoML offer efficient and streamlined fine-tuning solutions, eliminating the need for extensive infrastructure investments.
Other Tools
Various other tools play vital roles in LLM applications, such as labeling tools for fine-tuning with data samples, performance monitoring tools to track model responsiveness, and safety monitoring tools to prevent the promotion of harmful or biased content. The selection of these tools depends on your unique use case and requirements, ensuring a tailored approach to LLM application development and operation.

Final thoughts
In conclusion, building LLMs for enterprise applications demands a comprehensive approach that incorporates foundational understanding, customization, robust infrastructure, and strategic tool integration. As businesses embrace the transformative power of LLMs across various sectors, from customer service to data analysis, these intelligent language models are reshaping the digital landscape.
By selecting appropriate foundation models, fine-tuning them for specific use cases, setting up robust ML infrastructures, and augmenting with essential tools, enterprises can harness the full potential of LLMs. These applications not only streamline complex tasks but also pave the way for personalized customer interactions, data-driven decision-making, and innovative solutions.