Large Language Model definition
A Large Language Model (LLM) represents a powerful deep learning algorithm with the ability to handle a wide spectrum of tasks in natural language processing (NLP). These models harness transformer architectures and undergo extensive training on massive datasets, which is why they earn the label "large." This training equips them to recognize, translate, predict, or generate text and other forms of content.
Furthermore, LLM, sometimes known as neural networks (NNs), draw inspiration from the structure of the human brain. These neural networks function through interconnected layers of nodes, much like the neurons in our brains.
In addition to their proficiency in teaching artificial intelligence (AI) applications to human languages, LLM can be trained to excel in diverse tasks, such as understanding protein structures and writing software code, among others. Similar to the human brain, LLM must undergo pre-training and subsequent fine-tuning to excel in areas like text classification, question answering, document summarization, and text generation. Their problem-solving capabilities find application in fields like healthcare, finance, and entertainment, where LLMs serve a multitude of NLP applications, including translation, chatbots, AI assistants, and more.
Moreover, LLMs feature a vast number of parameters, analogous to the model's accumulated knowledge as it learns from training data. These parameters essentially represent the model's knowledge repository.
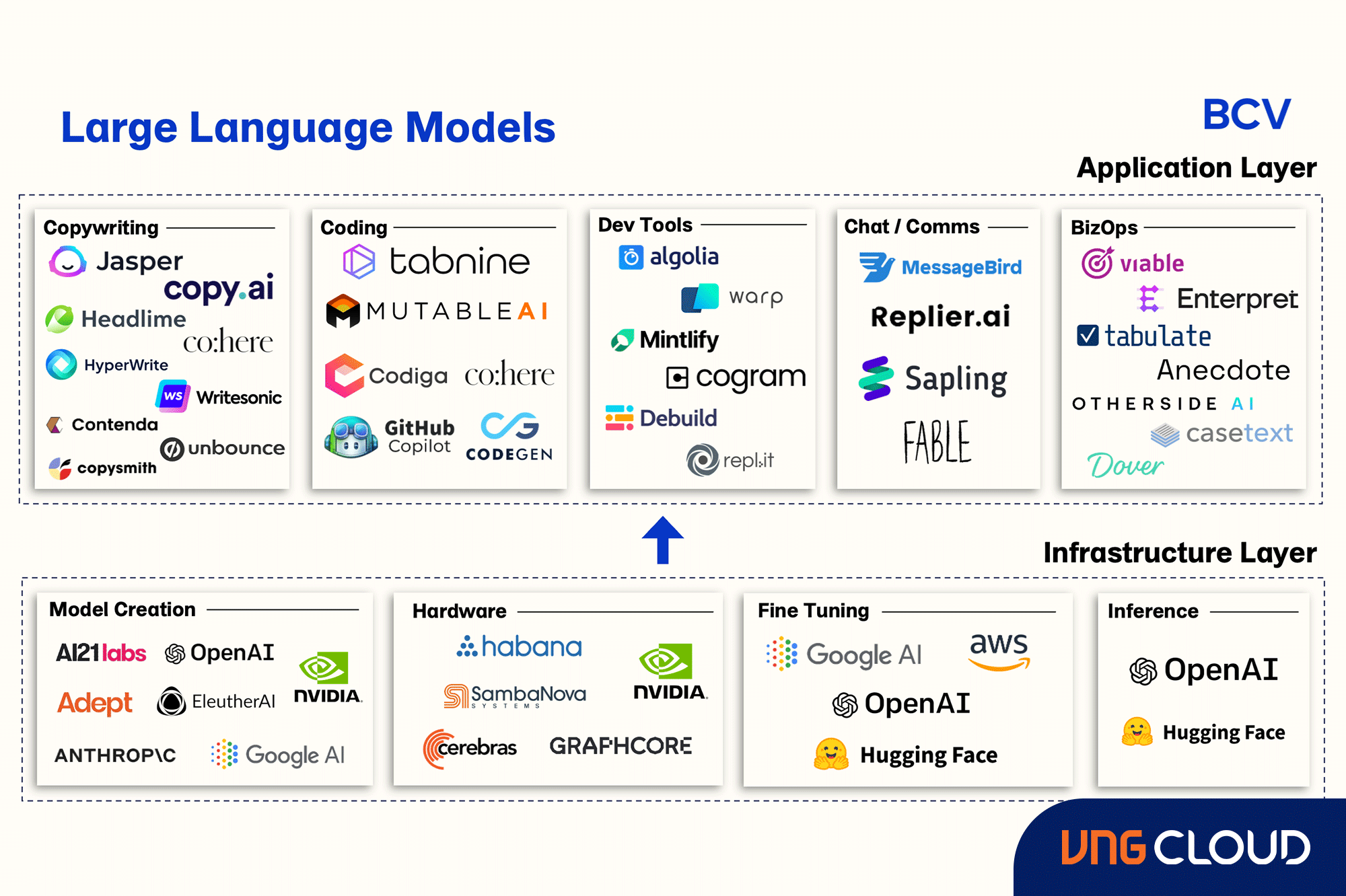
Essential components of Large Language Models
LLMs comprise a combination of distinct neural network layers, including recurrent layers, feedforward layers, embedding layers, and attention layers. These components work collaboratively to process input text and generate the desired output content.
- The embedding layer plays a pivotal role in constructing embeddings from the input text. This facet of the LLM captures both the semantic and syntactic nuances of the input, thereby enabling the model to comprehend context effectively.
- The feedforward layer, often abbreviated as FFN, consists of multiple fully connected layers responsible for the transformation of the input embeddings. These layers facilitate the extraction of higher-level abstractions, aiding the model in discerning the user's intent from the input text.
- The recurrent layer operates by sequentially interpreting the words within the input text. It excels at capturing the intricate relationships between words in a given sentence.
- The attention mechanism is a critical element that empowers a language model to focus on specific portions of the input text that are pertinent to the current task. This layer is instrumental in generating highly accurate outputs.
LLMs come in three primary categories:
- Generic or raw language models: These models predict the next word based on the language patterns observed in the training data. They are particularly well-suited for information retrieval tasks.
- Instruction-tuned language models: These models are specifically trained to predict responses based on the provided instructions within the input. This capability allows them to excel in tasks such as sentiment analysis or generating text or code in response to directives.
- Dialog-tuned language models: These models are tailored for engaging in dialogues and predicting the next response in a conversation. They find applications in scenarios like chatbots or conversational AI systems.
How do Large Language Models differ from Generative AI?
Generative AI is a broad category encompassing artificial intelligence models with the capacity to create diverse types of content, such as text, code, images, videos, and music. Prominent instances of generative AI comprise entities like Midjourney, DALL-E, and ChatGPT.
Within the realm of Generative AI, LLMs specifically pertain to models trained on textual data and proficient in generating textual content. ChatGPT stands as a prominent representative of generative text AI.
It's essential to acknowledge that all LLMs inherently fall under the umbrella of generative AI.

How do Large Language Models work?
LLMs, built upon transformer architecture, follow a process involving input encoding, decoding, and output generation. However, to function effectively, they undergo both training and fine-tuning stages.
- Training: Initially, LLMs are pre-trained using substantial textual datasets gathered from sources like Wikipedia, GitHub, and others. These datasets consist of an immense volume of words, and their quality significantly impacts the model's overall performance. During this pre-training phase, the model engages in unsupervised learning, processing the provided datasets without specific guidance. Throughout this process, the model's AI algorithm acquires an understanding of word meanings, word relationships, and contextual word distinctions. For instance, it learns to discern whether "right" implies "correct" or refers to the opposite of "left".
- Fine-Tuning: To equip LLM for specific tasks like translation, it must undergo fine-tuning tailored to that particular activity. Fine-tuning optimizes the model's performance in the context of specific tasks.
- Prompt-Tuning: This technique serves a similar purpose to fine-tuning, training the model for particular tasks using few-shot or zero-shot prompting. A prompt is essentially an instruction provided to the language model. Few-shot prompting involves teaching the model to make predictions based on examples. For instance, in a sentiment analysis scenario, a few-shot prompt might be structured as follows:
Example 1:
Customer review: "This skirt is so beautiful!"
Customer sentiment: Positive.
Example 2:
Customer review: "This skirt is so ugly!"
Customer sentiment: Negative.
The language model learns to discern the sentiment by grasping the semantic meaning of "ugly" and recognizing the contrasting example provided in the second case.
Alternatively, zero-shot prompting sets up the task for the language model without providing specific examples. For instance, a zero-shot prompt could frame the question as: Determine the sentiment in "This skirt is so ugly". This clearly outlines the task without offering problem-solving examples.
Large Language Models use cases
LLM can be found in a multitude of fields:
- Technology: LLMs play pivotal roles in diverse applications, from enhancing search engine capabilities to aiding developers in writing code.
- Healthcare and Science: These models possess the capacity to comprehend intricate elements such as proteins, molecules, DNA, and RNA. This proficiency empowers LLMs to contribute to the development of vaccines, the quest for cures for diseases, and the enhancement of preventative healthcare solutions. Additionally, they serve as medical chatbots for tasks such as patient intake and basic diagnoses.
- Customer Service: Across various industries, LLMs are harnessed for customer service purposes, including the deployment of chatbots and conversational AI.

- Marketing: Marketing teams leverage LLMs for tasks like sentiment analysis, swiftly generating campaign ideas, crafting persuasive text for pitching, and more.
- Legal: LLMs prove invaluable for tasks ranging from sifting through extensive textual datasets to generating legalese, offering significant assistance to lawyers, paralegals, and legal professionals.
- Banking: LLMs play a crucial role in supporting credit card companies in the detection of fraudulent activities.
Many businesses today have shifted from directly investing in hardware for LLM model training to using cloud infrastructure. This is considered as a smart and effective strategy for many businesses due to the following advantages:
- Cost-effective: Instead of investing in maintaining GPUs, businesses only need to pay for the resources they use with the "Pay as you go" model provided by cloud infrastructure.
- Flexibility: Cloud infrastructure enables businesses to rapidly and easily scale their usage of computing resources up or down, which is crucial in developing and testing with LLM models.
- Support from cloud providers: A comprehensive service, from resource provisioning to maintenance and technical support, cloud providers assist businesses in focusing on model development without worrying about technical issues or hardware maintenance.
Benefits of Large Language Models
LLMs offer a multitude of benefits, making them exceptionally valuable for addressing various challenges. Their communication style is clear and user-friendly, enhancing their utility.

Wide Range of Applications
These models find use in diverse applications, including language translation, sentence completion, sentiment analysis, question answering, mathematical problem-solving, and more.
Continuous Improvement
LLMs demonstrate an evolving performance as they expand with the accumulation of more data and parameters. In essence, they improve as they learn, and they can engage in "in-context learning." After pre-training, they readily adapt and acquire knowledge from prompts without the need for extensive additional parameters. This continuous learning process is a notable feature.
Rapid Learning
When it comes to in-context learning, LLMs exhibit swift learning capabilities. They adapt quickly without necessitating extensive additional weight, resources, or parameters for training. Their rapid learning ability is exemplified by their minimal requirement for examples.
Challenges of Large Language Models
While LLMs may create the illusion of comprehending meaning and delivering accurate responses, they are fundamentally technological tools and confront a spectrum of challenges.
Hallucinations
These models are susceptible to generating outputs that are erroneous or do not align with the user's intentions, a phenomenon known as "hallucination." For instance, they may falsely claim to possess human attributes, emotions, or affection for the user. Since LLMs primarily predict the next syntactically correct word or phrase, their interpretation of human meaning can fall short, resulting in these hallucinatory responses.
Security
Improper management and oversight of LLMs pose significant security risks. They can inadvertently disclose individuals' private information, engage in phishing schemes, and generate spam. Malicious users may reprogram these AI systems to promote their own ideologies or biases, contributing to the spread of misinformation with potentially dire global consequences.
Consent
LLMs are trained on vast datasets, some of which may not have been acquired with proper consent. They have been known to disregard copyright licenses, plagiarize content, and repurpose proprietary material without obtaining permission from the original creators. This lack of data lineage tracking and the absence of credit to creators can expose users to copyright infringement issues. Additionally, these models may inadvertently scrape personal data, compromising privacy and potentially leading to legal issues related to intellectual property.

Scaling
Scaling up and maintaining LLMs can be a formidable undertaking, involving substantial time and resource investments.
Deployment
Deploying LLMs necessitates expertise in deep learning, transformer models, distributed software and hardware, and overall technical proficiency, making it a complex process.
In summary, the use of LLMs presents several limitations and obstacles that necessitate careful consideration and management to ensure responsible and effective utilization.
Future advancements in Large Language Models
The emergence of ChatGPT has propelled LLMs into the spotlight, igniting discussions and contentious deliberations about their future trajectory.
As LLMs steadily enhance their proficiency in comprehending and generating natural language, concerns arise regarding their potential impact on the job market. It becomes evident that these models could acquire the capability to replace human workers in specific industries.
In capable hands, LLMs hold the potential to augment productivity and streamline processes, but their utilization raises ethical dilemmas within the realm of human society.