If you traveled back in time 25 years and spoke with a database administrator, they would likely emphasize the importance of a single monitoring metric: whether the infrastructure was up or down.
During that time, applications were typically monolithic and relied on tools like IBM Tivoli, CA Unicenter, or BMC PATROL to pull data on infrastructure metrics when an element failed. If a server went down, HP OpenView would send a health check alert, and the on-call technician would receive a notification.

Fast-forward to today, and we find ourselves in a world of clouds and increasingly intricate architectures. Infrastructure is elastic and virtualized, applications are composed of multiple interdependent services running open-source middleware that performs millions of tasks per minute, and updates are continually being shipped and reversed in Docker containers. The life expectancy of any resource in a scale-out architecture can be as short as an hour, while previous generations of scale-up architecture could run on the same machines for years.
The dynamic and distributed nature of modern applications has transformed monitoring into an analytics challenge. Autoscaling and load balancing have made it impossible to assess system health and performance based solely on server status and events. However, most organizations continue to apply this outdated framework to modern environments.
Maslow’s Hierarchy of Needs
Maslow's Hierarchy of Needs is a well-known framework taught in introductory psychology courses. According to this model, individuals must first satisfy their basic needs, such as water, food, and safety, before progressing up the pyramid through various stages to reach self-actualization, or the pursuit of their aspirations.
Interestingly, this framework is analogous to the needs of modern operations and monitoring. Organizations that are transitioning to the cloud, undergoing digital transformations, or adopting DevOps practices, focus on their future state rather than satisfying their current and most pressing needs first.

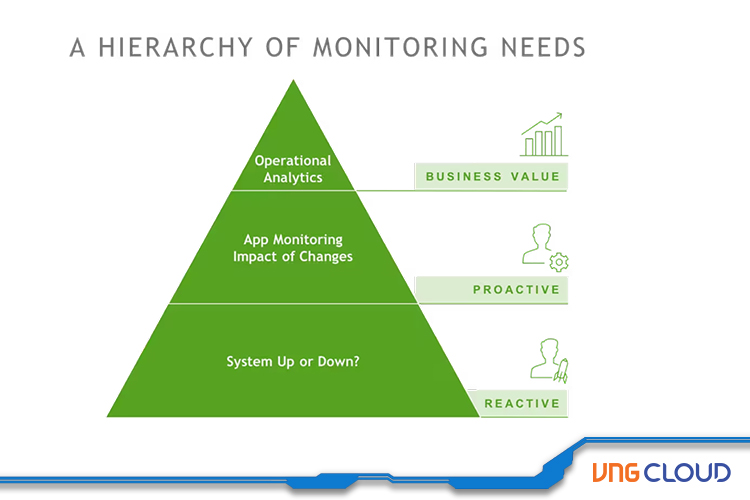
Similar to Maslow’s Hierarchy of Needs, Hierarchy of Monitoring Needs is divided into 3 layers, each of which must be addressed before moving to the next:
Reactive Monitoring: Which parts of your service are currently up or down?
Proactive Monitoring: Actively manage quality and performance. Identify and resolve issues before they impact users. Roll back changes or deploy fixes before a problem escalates.
Business Value: Correlate user and business metrics with infrastructure and application metrics to make informed decisions that lead to new outcomes and desired results.
Where Are We Today?
Monitoring has been a well-understood objective of business relevance in the context of traditional monolithic applications such as Oracle, Siebel, and SAP. Infrastructure management is simpler in a scale-up context. The metrics, and monitoring tools have had over 40 years to well-understood objectives of business relevance. However, among the handful of massive web-scale companies, only a few have achieved self-actualization in monitoring, reaching the higher stages of the hierarchy.
At the second level, organizations focus on self-service and performance monitoring for their applications, with product teams aligning development goals and roadmaps to operational metrics. New features are rolled out through canary deployments, and performance changes are benchmarked against scalability, load demand, and infrastructure size. Only big corporations like Facebook and Google have the visibility to confidently experiment with new deployment models.
For the vast majority of operations teams working with cloud applications, the first level of the hierarchy is still a struggle. Production monitoring is primarily focused on the fear of your customers or bosses finding out that a service is down before you do. Despite the reality that systems and applications go down, traditional monitoring tools are tailored to a more static environment and do not provide advance warning of troubling patterns in elastic infrastructures. The pace of change in scale-out architectures also requires constant reconfiguration of monitoring tools to update architecture changes, service membership, and alert rules.
Metrics Monitoring for Modern Environment
To conquer the fear of not knowing when a part of your distributed, elastic infrastructure has failed, a fresh monitoring approach is necessary. By shifting from a static to a metric view of your infrastructure, your entire organization can aggregate and interact with a wide range of real-time streaming data across the entire stack. This allows you to alert on any abnormal metric and compare it to historical patterns and populations to evolve your signal as your services and infrastructure change.
After you've applied significant metrics and alerts to your modern environment and overcome the most basic challenges associated with the pace of change, you'll have the tools to progress to the next levels of the monitoring hierarchy and to adopt a more meaningful analytical approach to both your infrastructure, application operations, as well as your business and customer objectives. Ultimately, operational intelligence is based on the ability to ask the right questions and correlate data from multiple sources into a single, real-time view. Some of the questions you might ask include:
How will a 5% increase in latency for my login service affect user retention?
If the load capacity for my mobile transactions service is 25% higher than the same time last year, but demand is 45% higher, what will be the effect on revenue?
How many standard deviations below the mean for throughput on my service before missing an enterprise SLA?

As new applications are developed in the cloud with distributed, scale-out architectures, monitoring objectives will undoubtedly broaden, and web-native organizations will plan for some of the higher-level needs already seen in more traditional, static environments. However, today, the vast majority of enterprises are beginning to transition to elastic, ephemeral environments. Understanding the fundamental needs of operating a modern infrastructure and application, as well as how they differ from the needs of legacy infrastructures and applications, is among the most critical steps towards cloud-readiness.
With a new approach to measuring, observing, analyzing, and alerting on cloud data - aligned to the sophistication of modern architectures but aiming to remove the complexity of monitoring them - you can self-actualize and rise to the top of our Hierarchy of Monitoring Needs.
vMonitor Platform of VNG Cloud is a cloud-based monitoring and management platform designed to help businesses optimize their IT infrastructure and ensure maximum system performance. vMonitor Platform offers a range of powerful features and tools for monitoring and managing network devices, servers, and applications across multiple locations.